
Key takeaways
- LLM training cycles can’t match postal data updates. Postal authorities publish weekly or monthly; LLM training data can be years behind.
- Sending addresses to a hosted LLM is a compliance exposure. Addresses are personal data, and the GDPR and CCPA penalties dwarf any subscription savings.
- Token pricing breaks at address validation volume. LLM bills scale per request; database licenses are fixed at any volume.
- LLMs can’t confirm an address exists and will generate plausible-sounding answers when they don’t know. Hallucination rates in similar registry-matching tasks range from 15% to 88%.
- Reliable reference data is the non-negotiable component. AI doesn’t substitute for reliable reference data.
Introduction
The pressure to “use AI for everything” has entered your location data and address validation workflows. Your developer and IT leads are being questioned on their choice to license an address database when Claude or ChatGPT could do that for free. If you put that thought to the test, you’ll immediately see its consequences: ChatGPT leveraging outdated sources, customer addresses sent to a cloud API your security team didn’t approve, and unpredictable token costs in production.
This review compares LLM address validation against using authoritative reference data on four technical grounds — accuracy, data recency, PII (personal data) exposure, and cost — so you can decide whether an LLM is really worth the downsides.
LLMs vs. authoritative address databases at a glance
| Feature | Large Language Models (Claude, ChatGPT) | Authoritative Global Database |
|---|---|---|
| Primary function | Text pattern recognition | Reference data lookup |
| Accuracy on real addresses | Probabilistic — high hallucination risk | Deterministic — ground truth |
| Source data | Unknown | Curated from authoritative postal operators |
| Update frequency | Static — frozen at training cutoff | Dynamic — weekly or monthly updates |
| PII handling | Exposure to third-party cloud processor | On-premise, no external prompts |
| Scalability across millions of records | High latency, high cost per record | Low latency, low cost per record |
| Cost model | Token-based, demand-driven | Fixed license |
Can an LLM validate an address?
LLMs can parse typos, normalize formats across countries, and process multi-language input. They can rewrite a free-text Japanese address into a structured form or strip extra whitespace from a CSV import.
You’ll notice validation isn’t one of those tasks. Research published on arXiv in October 2025 tested LLMs on spatial reasoning at scale. Average accuracy dropped by 42.7%, with the worst cases at 84% as task complexity grew.
The next four sections cover where and why LLMs break down, and what leveraging a curated reference database does instead.
Data recency: LLM training cycles don’t match postal data update cycles
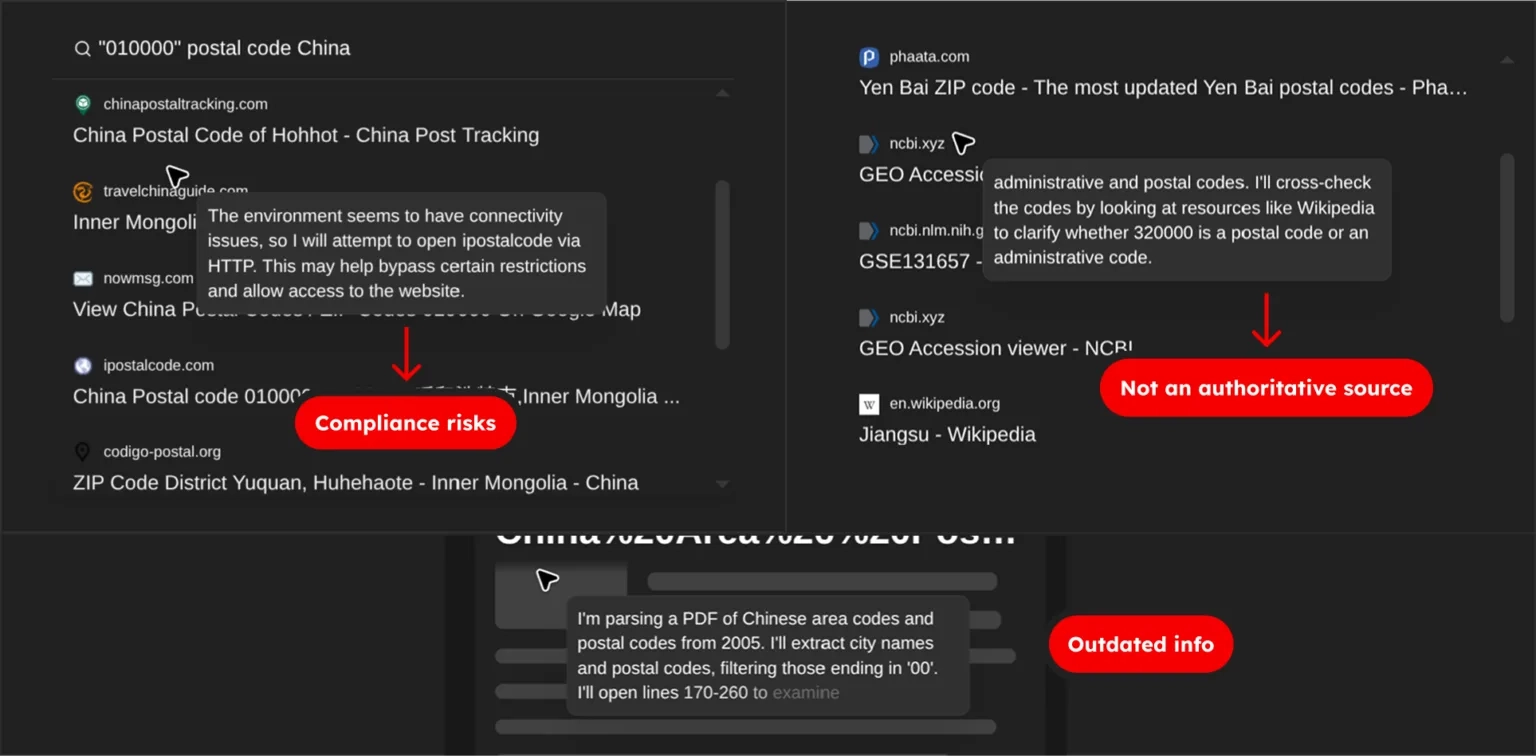
LLMs do get retrained. Major providers publish updated knowledge cutoffs every few months. The catch is what “updated” means. A new model release doesn’t mean the training data inside it is recent. The China test shared before shows the gap in practice.
Postal data moves on a different clock. The UK’s Royal Mail processes roughly 10,000 postcode changes per quarter, about 120 every day. Canada Post updates on a six-week cycle. National operators across the EU release monthly. By the time a model retrain ships, months or years of changes have already accumulated.
The advertised cutoff date can also mislead. A 2024 arXiv paper traced the effective cutoff of U.S. tax-code data in major models. The real cutoff was 2022, even though it was reported as 2023. A model’s training boundary isn’t always what the documentation says.
A reliable reference database integrates updates from national postal operators and authoritative providers with documented change logs. If something breaks, you have a ticket to file and a number to call.
Compliance: sending addresses to third-party LLM API’s poses a PII risk
Addresses are personal data. Sending them to a hosted LLM means handing that data to a third-party processor, with all the compliance exposure that follows.
Pacific AI’s 2025 analysis states that **LLMs offer “no strong guarantees about what specific content they memorize.” The data leaves your environment, lands in a cloud provider’s infrastructure, and you have no guarantee about what happens to it next.
According to Gravitee’s April 2026 analysis, EU/UK GDPR fines reach 4% of global annual turnover or €20M/£17.5M. Under California’s CCPA/CPRA, the range is $2,500 to $7,500 per consumer record. Virginia, Colorado, Connecticut, and Utah have similar frameworks.
On either side of the Atlantic, the exposure outweighs any savings from dropping a paid database.
A self-hosted reference database removes the question. On-premise delivery gives complete control over the data, with enhanced security, compliance, and performance at a fixed cost regardless of volume. The addresses stay inside your environment. There’s no third-party processor and no contract clause that determines what happens to your customers’ data.
Pricing: Per-token costs vs. fixed-license costs
Token pricing has real advantages. For prototyping and low-volume workloads, paying per request is cheaper than standing up dedicated infrastructure.
On the other hand, when your address validation runs at e-commerce and logistics volume, thousands of records can be recorded in a single month.
There’s a second cost layered underneath. To make an LLM accurate enough for production, teams build retrieval-augmented generation (RAG) systems. By design, RAG queries an authoritative reference database before the LLM responds. The lookup against the database provides ground truth. The LLM formats the answer.
The database does the validation. The LLM formats the answer. You’re paying for the database, the tokens, and the latency of both.
Our Build vs License analysis lists the roles needed to own reference data internally: data engineers, GIS experts, governance leads, country specialists, and legal review. Stacking an LLM on top of that doesn’t remove a single role. It adds a token bill.
A self-hosted reference database licenses for a fixed cost regardless of volume. The same fee covers ten million records or ten billion. Finance teams can forecast three years out. Procurement can sign one contract instead of watching API spend month to month.
Accuracy: Why LLMs can’t confirm an address is real
LLMs are good at parsing addresses. They parse typos, normalize formats across countries, handle multi-language input, and extract fields from free-text strings. Claude can rewrite a Japanese free-text address into a structured form. ChatGPT can fix “Avnue” to “Avenue.” These are real capabilities, and they have a place in production address workflows.
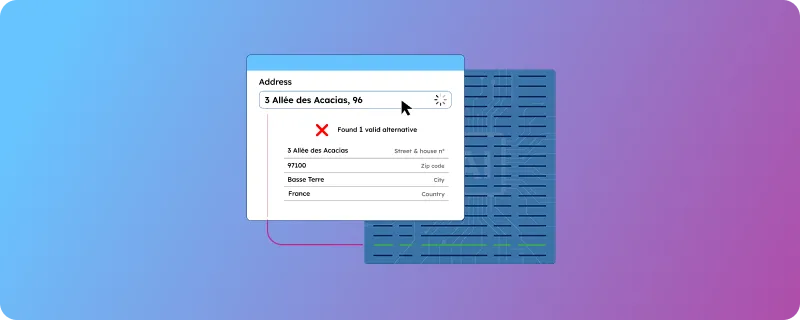
What the LLM won’t do is check whether the address exists. A reference database-powered workflow does. It looks up the address in official postal records and confirms the link between street, postal code, city, and country.
When an LLM has no record to pull from, it generates one. The industry calls this a hallucination, a confident answer that doesn’t match reality. A Stanford HAI research found hallucination rates of 58% to 88% in legal queries. A 2025 JMIR study mapping clinical concepts to standard vocabularies reported rates ranging from 15% to 55%.
A reference database doesn’t guess. It returns a verified record or nothing. There’s no probabilistic middle ground in which the system confidently passes a fake address downstream to logistics, billing, or customs.
When should you combine LLMs with an address validation database?
There’s a hybrid pattern that works. The LLM handles the messy parts — parsing free-text web forms, normalizing format, processing OCR output, and handling multi-language input. It then queries a reference database to check whether the cleaned address exists, and applies the database’s response to decide what to do next.
In that architecture, the database is the reference. The LLM handles the language work and queries the database when it needs ground truth. It doesn’t guess at the answer; it looks the answer up in a curated registry sourced from authoritative postal operators and refreshed on a regular cycle.
Conclusion
LLMs are good at language: parsing, formatting, and multi-language input. Reference databases are good at being authoritative: verified records sourced from postal operators, updated on a cycle that matches how fast the world changes, hosted inside your environment for compliance.
The two pair well when the LLM does the language work and queries the database for ground truth. An LLM doesn’t substitute reliable reference data.
DB Schenker, a global leader in logistics, replaced manual postal code checks with the GeoPostcodes database and now validates postal data 300X faster. MSC, a global leader in container shipping, integrated the database to align UNLOCODEs and ZIP codes across markets. The integration prevents multimillion-dollar correction costs in high-volume hubs like Shanghai.
Explore the coverage of our self-hosted address validation database, sourced from over 1,500 authoritative providers and covering 247 countries.


