
The Model Context Protocol (MCP) is an open-source standard that enables Large Language Models (LLMs) to access files, databases, and APIs.
The MCP has seen remarkable adoption since its release in November 2024. MCPs are a bridge between language models and the external world. They promise an interface made for LLM-based AI systems to discover and use external tools. MCP clients such as Claude, Cursor, and ChatGPT now integrate with MCP servers, enabling AI to interact with everything from calendars to APIs.
But early implementations have exposed challenges. As Kent C. Dodds (world-renowned coding expert and speaker) observes, MCP has entered its natural critique phase, similar to early web browsers that were slow and inefficient but evolved into today’s dominant platform. The protocol works; people use it extensively every day. We’re now in the phase of making it right, then making it fast.
While LLMs and MCP handle data reasonably well, they struggle to grasp the difference between reference data and other data. Within reference data, location information is the hardest test case.
This isn’t a critique of MCP as a specification. It’s a reality check on what happens when AI systems attempt to reason about structured, authoritative data that must be correct. Understanding these challenges is essential to building implementations that work reliably in production.
| Term | Definition |
|---|---|
| LLM (Large Language Model) | A deep neural network trained on large text sources to generate and understand language by predicting the next token in a sequence. |
| MCP Server (Model Context Protocol Server) | A server that exposes structured tools, data, or external capabilities to an LLM via the Model Context Protocol, enabling controlled tool execution and context retrieval. |
| MCP Client | A component that connects an LLM to one or more MCP servers, handling tool discovery, request routing, authentication, and response formatting. |
| AI Client | A software application that interacts with an AI model via an API, managing prompts, sessions, context handling, and response processing. |
| Token | The smallest unit of text processed by an LLM (word, subword, character, or punctuation). Input and output length, cost, and limits are measured in tokens. |
| Context (Context Window) | The total number of tokens an LLM can process in a single interaction, including instructions, user input, and model output. Exceeding the limit results in truncation or errors. |
| Agent workflow | A structured process in which an LLM iteratively plans, reasons, and executes actions (e.g., calling tools or querying data) to accomplish a multi-step task, often using feedback loops and intermediate state tracking. |
Understanding MCP
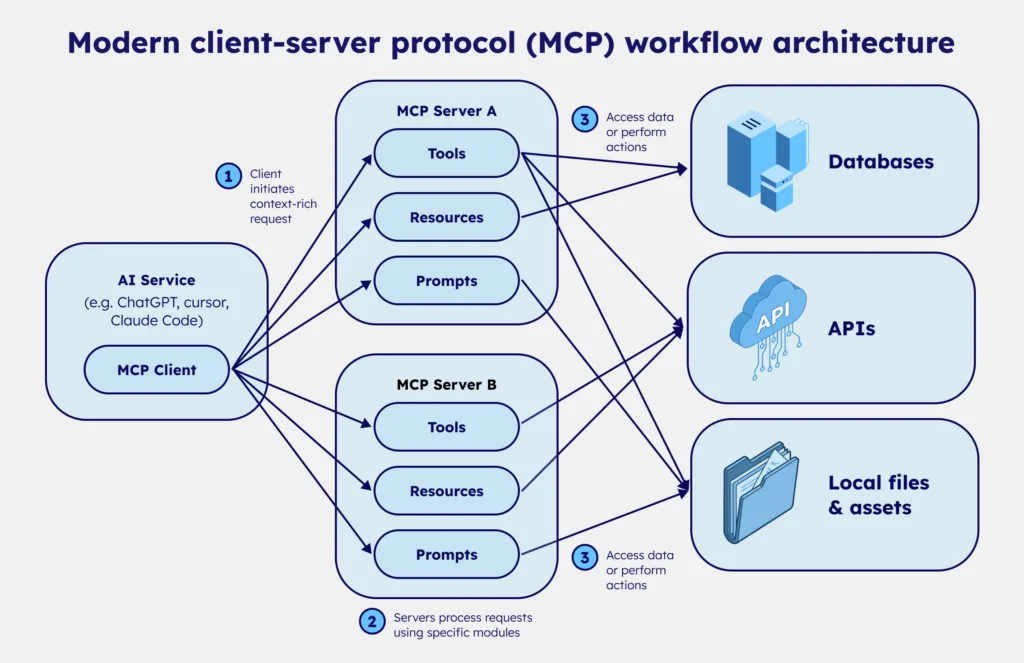
The Model Context Protocol defines two key components: MCP clients and MCP servers. Clients are embedded in AI tools like Claude, Cursor, or custom applications. Servers are hosted by organizations providing data or tools for LLM consumption.
When an LLM needs external capabilities, it uses its client to connect to an MCP server, discover available tools and resources, and determine how to leverage them to complete its task. The protocol standardizes this discovery and invocation process, making it theoretically simple to connect AI to any service.
The elegance of this design explains MCP’s rapid adoption. But the protocol itself is only infrastructure. What matters is what flows through it.
The challenge of using MCPs with location data
Reference data is structured, authoritative, and foundational. It’s the kind of information systems rely on to function. Location reference data—postal codes, administrative boundaries, time zones, and coordinates—is a clear example. Unlike conversational text, reference data must be correct.
Geographic information also involves complex hierarchies: cities contain neighborhoods, regions contain cities, and countries contain regions. These relationships are not always straightforward. Postal codes may span multiple cities. Administrative boundaries change. Place names may have translations, alternatives, or historical versions still in use.
Location data is also constantly evolving. Postal codes are introduced and retired. Municipalities merge or split. Administrative divisions are redrawn. What appears to be a stable dataset is, in reality, continuously changing.
Reconciling location data requires judgment, not just aggregation. For example, municipalities may have both current and historically used names, and administrative divisions can be redrawn while legacy systems still reference old codes. Maintaining both accuracy and backward compatibility requires careful structuring.
These decisions require domain expertise. Without that expert-level context, LLMs are likely to provide incorrect answers confidently, also known as hallucinations.
The hallucination problem with location data in LLMs
LLMs generate responses through statistical analysis of their training data. They identify patterns and generate text that follows them. For most conversational tasks, this works well. For reference location data, it creates a fundamental problem.
The location data in LLM training sets is often outdated, inconsistent, or incomplete. Models have no mechanism to recognize this; they don’t know which information is current and which is stale. They can’t distinguish authoritative sources from casual mentions. They simply generate responses that match statistical patterns in what they’ve seen.
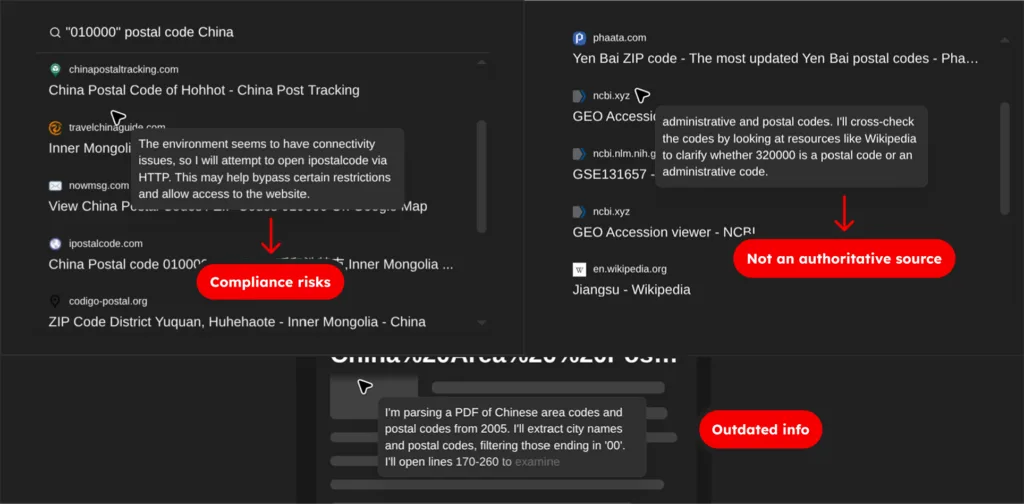
Consider postal codes in China. The country maintains alternative postcodes for certain administrative divisions, but information about these is intentionally opaque. When we cross-referenced available sources and compared them to AI-generated responses, we found significant discrepancies. The AI confidently provided postal codes that didn’t match any authoritative source. It wasn’t lying; it was generating statistically plausible patterns based on incomplete training data.
This is where ‘plausible but incorrect’ becomes catastrophic. A customer service system that routes packages based on AI-provided postal codes will send them to the wrong place. A logistics platform that validates addresses against hallucinated data will reject legitimate locations. An analytics system that aggregates data by administrative division will produce meaningless results when the boundaries are wrong.
The common response of “just use Google Maps or OpenStreetMap” doesn’t solve this. These sources are popular, but they’re neither comprehensive nor consistently up to date. Google Maps excels at user-generated content and navigation, but it’s not an authoritative source for postal boundaries or administrative hierarchies.
OpenStreetMap is crowdsourced and varies wildly in coverage and accuracy across regions. Both have strengths, but neither replaces curated reference data for production systems that require correctness.
Agent workflows cascade reference location data issues
The hallucination problem is magnified when AI operates autonomously through agent workflows. In a chatbot conversation, a human can catch errors. A user asks for a postal code, the AI hallucinates, the user notices something seems wrong, and the conversation ends. The error is contained.
Agents don’t work this way. They’re given tasks to complete. When an agent retrieves a postal code and uses it in subsequent operations, there’s no human verification between steps. The agent operates under the assumption that its data is correct.
This creates cascading failures. Let’s take an example with an agentic workflow in a logistics company. An agent uses a hallucinated postal code to validate an address. The validation fails. The agent retries with another plausible but incorrect code. That also fails. It logs the package to a fallback facility based on incomplete information.
The logistics system updates inventory records. Confirmation emails are sent with incorrect tracking information. Customer service receives tickets about missing packages. By the time humans notice, the error has propagated through multiple systems, each one trusting the previous step’s output.
The scale compounds the problem. Agents can execute thousands of operations per hour. A single incorrect postal code may affect a single package. A systematic error in an agent’s interpretation of administrative boundaries could misroute an entire region’s logistics for days before anyone notices the pattern.
This is why deterministic tools backed by curated data become critical in agent workflows. The cost of an error isn’t just one wrong answer; it’s a chain of downstream failures, each one harder to detect and more expensive to fix.
The challenge of choosing a reliable data source
Even outside of MCP and AI systems, maintaining reliable location data is difficult. Postal codes, administrative divisions, boundaries, and coordinates form one of the most critical reference data domains because they underpin logistics, taxation, reporting, and regulatory processes. Maintaining this data requires significant effort and expertise.
Postal systems evolve constantly: municipalities merge or split, administrative boundaries change, and postal codes are introduced or retired. Ensuring accuracy requires continuous validation against authoritative sources.
Many organizations underestimate this effort. When reference data becomes fragmented, outdated, or inconsistent across systems, downstream platforms inherit those inconsistencies. Because maintaining this layer requires continuous reconciliation of multiple authoritative sources, many organizations rely on specialized data providers that curate and maintain global location reference datasets.
💡 Reliable AI workflows start with reliable reference data. GeoPostcodes maintains one of the most comprehensive global postcode and administrative datasets, curated from authoritative sources and continuously updated to ensure accuracy across systems. Explore our datasets and discover how high-quality location data supports reliable MCP and AI.
MCP design matters: Tools vs. raw data exposure
As Kent C. Dodds notes, as AI agents become the primary “clients,” most developers won’t build the clients themselves. Instead, they’ll build MCP servers that expose their own system’s capabilities—data, actions, and rules—in a structured way that AI clients can discover and use.
This mirrors the web: few developers build browsers, many build websites. When improvements happen on the client side—such as code execution modes—they automatically enhance how users interact with well-designed servers. The standard interface MCP provides makes these optimizations possible.
Many early MCP servers simply wrap or mirror existing APIs with minimal adaptation. As Adam Gospodarczyk (agent workflow expert) explains, this approach creates fundamental problems. APIs designed for programmers are not APIs designed for language models. Programmers understand context, have documentation, and can interpret ambiguous responses. LLMs operate on the immediate context within their window.
Consider a simple postal code lookup. A typical API might return:
{ "postcode": "1000", "city_id": 42, "success": true }For a human programmer, this is fine. They know city_id 42 refers to Brussels because they have context from previous calls or documentation. For an LLM, city_id 42 is meaningless. It would need to make another API call to resolve the ID, which would consume more tokens and increase error risk. And “success”: true provides no actionable information. This example showcases partial information and clutter.
A well-designed MCP server for location data would return:
{ "postcode": "1000", "city": "Brussels", "region": "Brussels Capital", "country": "Belgium", "url": "<https://geopostcodes.com/BE/1000>" }Now the LLM has everything it needs in one response: human-readable names, hierarchical context, and a reference URL. No additional calls required. No ambiguity about what the data represents.
LLM token efficiency matters too. Every MCP response consumes context window space, the limited number of tokens an LLM model can “see” and reason over at one time while answering a request. MCP servers that expose dozens of granular endpoints force the LLM to process extensive tool lists, even when most aren’t relevant.
Progressive disclosure, letting the AI client’s LLM discover tools only when needed, significantly reduces additional token consumption.
For teams using location data, there’s a fundamental trade-off between passing raw geographic data to an LLM and relying on opinionated tools that return well-defined, authoritative results. Raw data dumps allow maximum flexibility but require the LLM to interpret, validate, and structure information, all operations prone to error.
Deterministic tools that perform validation, lookup, and formatting server-side return structured, verified results. The AI client simply presents them to the user.
This is the difference between a generic MCP API wrapper and a use-case-oriented MCP server. Generic MCP wrappers tend to map MCP directly onto existing APIs, passing requests and responses through with minimal adaptation, rather than reshaping them around clear, model-friendly capabilities.
Use-case-oriented servers are designed to support how LLMs will consume them, minimizing token usage, reducing error rates, and delivering actionable responses.
Conclusion: Use-case-driven MCP design with quality location data
Your MCP’s maturity depends on parallel evolution in two areas: server design and data quality.
Well-designed MCP servers are tailored to specific use cases, not generic wrappers around existing non-MCP optimized APIs. They minimize token consumption, return actionable responses, and reduce errors. They understand that serving an LLM is fundamentally different from serving a programmer.
MCP amplifies the consequences of poor data. When LLMs interact with APIs, stale or inconsistent data produces wrong answers and propagates errors at scale through hallucinations and misinterpretation.
This is why curated datasets with active governance become more critical in AI workflows. An expert provider, like GeoPostcodes, needs to cross-reference sources, track changes over time, and maintain data freshness. AI can’t do this work reliably because it requires knowing which sources are authoritative—knowledge that comes from domain expertise, not statistical patterns.
Browse our curated reference datasets in the GeoPostcodes portal.

