

Introduction
For companies operating globally or expanding into new markets, reliable location data isn’t just a nice-to-have – it’s a critical foundation for success. Whether you’re validating addresses, optimizing delivery routes, or analyzing market coverage, the quality of your location data directly impacts your operational efficiency and bottom line.
As businesses increasingly rely on location-based services, many turn to open-source location databases as a starting point. These resources can seem attractive due to their accessibility and zero upfront cost. However, understanding their capabilities, limitations, and appropriate use cases is crucial for making informed decisions about your location data strategy.
💡 Build your operational framework over a reliable layer of location data. For over 15 years, GeoPostcodes has delivered the most comprehensive worldwide postal code database, trusted by enterprises for address validation, supply chain optimization, geocoding, and map visualization. Explore our datasets and download a free sample to see the difference standardized data makes.
This article will guide you to explore the world of open-source location data and examine how it fits into the broader landscape of location intelligence solutions.
| Source | Geographic Coverage | Update Frequency | Data Validation | Postal Code Coverage | Integration Capabilities | Best Use Case | Data Format | Technical Expertise Required | Additional Features | Considerations |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenStreetMap (OSM) | Global | Real-time community updates | Community-driven | Available where contributors have mapped | Extensive API support | Digital mapping and routing | Multiple formats (XML, JSON, etc.) | Moderate to High | Points of interest, roads, buildings | Community-driven structure; coverage depth vary by contributor and country |
| GeoNames | 96 countries | Varies by region | Basic validation | Comprehensive, with regional depth tied to contributors | Basic API access | Global place name lookup | Text/CSV | Low to Moderate | Place names, elevation data | Community-maintained; postal coverage depth varies by region |
| US ZIP Code Database | United States | Periodic updates | USPS-maintained | Complete U.S. coverage | Database download | U.S. address validation | CSV/Database | Low | Basic demographic data | U.S.-only; pair with other datasets for international coverage |
| HDX (Humanitarian Data Exchange) | Global (humanitarian focus) | Crisis-driven updates | Strict UN protocols | Varies by region | API and bulk download | Humanitarian operations | Multiple standardized formats | Moderate | Humanitarian indicators | Contributor frequency and dataset structure vary across humanitarian programs |
| Natural Earth | Global | Periodic releases | Standardized cartographic dataset | No postal codes | GIS-compatible formats (Shapefile, GeoJSON) | Cartography and global geographic reference | Shapefile, GeoJSON | Low | Physical geography, administrative boundaries | Cartographic resolution; pair with other sources for postal codes or address data |
| GADM | Global | Periodic releases | Curated by researchers | None (administrative boundaries only) | GIS-compatible formats | Administrative boundary analysis | Shapefile, GeoPackage, KMZ, R-raster | Moderate | Multi-level administrative hierarchies | Academic/non-commercial license; commercial use requires separate licensing |
| Python Libraries | Varies by library (mostly U.S.-focused, except Geopy) | Varies (Pyzipcode: limited, Uszipcode: semi-regular, Geopy: API-dependent) | Basic validation (Pyzipcode), Enhanced (Uszipcode, Geopy API-based) | Pyzipcode: Basic U.S., Uszipcode: Comprehensive U.S., Geopy: API-dependent | Python libraries (some require database downloads) | Python-based postal lookups, geocoding, spatial analysis | Python objects (Pyzipcode, Uszipcode), API responses (Geopy), Geometric data (Shapely) | Low to Moderate (varies by library) | Geopy: Global geocoding, Uszipcode: U.S. Demographics, Shapely: Spatial analysis | Pyzipcode is not actively maintained, Uszipcode is U.S.-only, Geopy relies on external APIs |
What is open-source location data, and how is it curated?
Open-source location data refers to geographic datasets that are publicly available under open licenses. These datasets typically include information such as place names, administrative boundaries, coordinates, roads, and points of interest. Because the data is distributed under open licenses, it can usually be accessed, modified, and reused without commercial restrictions, depending on the specific license terms.
Most open-source location data is created and maintained through community-driven contributions or publicly funded initiatives. Volunteer contributors map roads, cities, and infrastructure, while public institutions may release geographic data collected for administrative or statistical purposes. This collaborative model enables broad global coverage, but it also means that data quality, update frequency, and standardization can vary by country or region.
Factors for evaluating open-source location databases
Understanding how to evaluate open-source location data becomes crucial as your business requirements grow. Let’s examine the critical factors that should influence your decision-making process.
Data quality and accuracy
Data quality in open-source location databases operates on multiple levels. Beyond basic accuracy, businesses need to consider completeness, consistency, and timeliness.
Think About It: When evaluating data quality, consider these questions:
- How complete is the coverage in your target markets?
- What verification processes are in place?
- How quickly are updates implemented?
- What is the source of the original data?
- Can I legally use this data commercially?
- Can I keep this data accurate and up-to-date?
- Will I need support in ensuring the quality of the data as well as implementing it?
The reality is that open-source data quality varies significantly based on region and contributor activity. Urban areas typically show higher quality due to more frequent updates and verification, while rural areas may suffer from outdated or incomplete information.
Maintenance and updates
The maintenance model of open-source location data presents unique challenges. Unlike commercial solutions with dedicated update schedules, open-source databases rely on community contributions and voluntary maintenance.
Real-World Impact: Changes in postal codes, street names, or administrative boundaries can have immediate business implications. A delay in updating this information can lead to failed deliveries, customer dissatisfaction, and increased operational costs.
Data format and standardization
The challenge of data standardization becomes especially evident when businesses integrate open-source location data from multiple sources. Differences in attribute definitions, table structures, coordinate projections, and geometry types can introduce inconsistencies that require significant preprocessing before use.
For example, administrative boundaries from different datasets may use varying classification levels—one source might define a “region” as a first-level administrative division, while another labels it as a “province.” Similarly, some datasets provide polygon geometries for boundaries, while others only include centroids. These inconsistencies make direct comparisons and integrations difficult without additional transformation efforts.
Even within the same country, location datasets may use different projections, making spatial analysis challenging without proper conversion. Some sources use latitude/longitude (WGS84), while others rely on national coordinate reference systems.
Important considerations for open-source location databases
- Can I keep this data accurate and up-to-date? Open-source datasets evolve at different rates. Some may update in real-time (OSM), while others are refreshed sporadically (GeoNames, Natural Earth). Businesses must establish processes for monitoring updates and integrating new data.
- Will I need support in ensuring the quality of the data as well as implementing it? Managing location data quality requires dedicated resources, either in-house expertise or external support. Organizations should assess whether they have the technical capacity to clean, validate, and maintain the data or if they need third-party solutions to ensure ongoing accuracy.
Successful use of open-source location data depends on acquiring the data and actively maintaining and refining it to meet business needs.
Data licensing and usage rights
It is important to note that open-source data does not mean you may use it for everything. Each dataset is available through specific license terms, indicating what use of the data is permitted. It is critical that you check the license before working with the data.
Here’s a summary of the licensing terms for the major open-source location databases:
| Database | License | Key Restrictions |
|---|---|---|
| OpenStreetMap (OSM) | Open Database License (ODbL) | Requires attribution and share-alike (derivative works must use same license) |
| GeoNames | Creative Commons Attribution 4.0 | Requires attribution; some datasets have additional restrictions |
| US ZIP Code Database | USPS licensing terms | Restrictions on redistribution and commercial use |
| HDX | Various (dataset-dependent) | Some datasets restricted to humanitarian/non-commercial use |
| Natural Earth | Public Domain | No restrictions, free for any use |
| GADM | Academic/Non-commercial license | Commercial use requires special permission |
For businesses, failing to comply with these licenses can result in legal and financial risks. Before using open-source location data commercially, it’s essential to:
- Verify if commercial use is permitted
- Thoroughly review the specific license terms
- Ensure compliance with attribution requirements
- Check if derived products must be shared under the same license
Top open-source location databases
In this section, we’ll explore seven major open-source location databases, each offering distinctive capabilities for different business applications. Understanding how each database’s features align with your specific requirements will help you determine which resources best complement your location data strategy.
Before diving into specific databases, it’s helpful to understand the different types of geospatial data they contain:
- Point Data: Single locations represented by coordinates (latitude/longitude), such as city centers, addresses, or points of interest.
- Line Data: Connected points forming features like roads, rivers, or boundaries.
- Polygon Data: Closed shapes representing areas like administrative boundaries, postal code zones, or building footprints.
- Text/Attribute Data: Non-spatial information attached to geographic features, such as place names, postal codes, or demographic information.
Each database below contains different combinations of these data types, making them suitable for different business applications.
OpenStreetMap (OSM)
About the provider: OpenStreetMap is one of the most recognized names in open-source mapping and geospatial data. Think of it as the Wikipedia of maps, a collaborative project where volunteers worldwide contribute geographic data. This crowdsourced approach has created an extensive database of roads, buildings, and points of interest.
The community-driven nature of OSM shapes both its strengths and the considerations that come with using it.
Strengths: Detailed, frequently updated information in urban areas where contributor density is high. Major cities often have street-level accuracy that rivals commercial solutions.
Considerations: This same characteristic leads to significant variation in rural areas, where fewer contributors may result in less frequent updates and potential gaps in coverage. The structure is community-governed rather than centrally standardized, with mapping conventions, tagging and levels of detail that vary by region.
Teams typically apply their own normalization layer when integrating OSM into business systems.
Real-world scenario: A logistics company using OSM for route planning in Europe may benefit from strong coverage in major cities, while rural areas tend to evolve more slowly, depending on local mapper activity. As a result, drivers can encounter outdated or missing information outside urban centers, potentially leading to delivery delays and customer dissatisfaction. Road classifications and address formats can also vary across contributor communities, which is something automated processing pipelines need to account for.
| Feature | Details |
|---|---|
| Geographic Coverage | Global |
| Update Frequency | Real-time community updates |
| Data Validation | Community-driven |
| Postal Code Coverage | Available where contributors have mapped |
| Integration Capabilities | Extensive API support |
| Best Use Case | Digital mapping and routing |
| Data Format | Multiple formats (XML, JSON, etc.) |
| Technical Expertise Required | Moderate to High |
| Additional Features | Points of interest, roads, buildings |
| Considerations | Community-driven structure; coverage depth and data structure may vary by contributor and country |
GeoNames
About the provider: GeoNames is another significant player in the open-source location data landscape. This database links places to postal codes across many countries, offering a foundation for basic location services.
Strengths: What sets GeoNames apart is its hierarchical structure of place names and administrative boundaries. For instance, you can trace the relationship between a city, its region, and its country, making it valuable for fundamental geographic analysis.
Considerations: GeoNames provides postal code data across 96 countries, but its coverage depth and update frequency vary by region based on community contributions. Postal code accuracy and timeliness reflect what each contributing community has published. Some countries have comprehensive, up-to-date information while others may suffer from outdated or incomplete coverage. This disparity can impact applications that rely on precise postal code validation.
Teams that need uniform postal code accuracy across all countries typically pair GeoNames with additional reference sources or use a curated commercial dataset.
| Feature | Details |
|---|---|
| Geographic Coverage | 96 countries |
| Update Frequency | Varies by region |
| Data Validation | Basic validation |
| Postal Code Coverage | Available where contributors have mapped |
| Integration Capabilities | Basic API access |
| Best Use Case | Global place name lookup |
| Data Format | Text/CSV |
| Technical Expertise Required | Low to Moderate |
| Additional Features | Place names, elevation data |
| Considerations | Community-maintained; postal coverage depth varies by region |
Uszipcode Database
About the provider: The Uszipcode database provides specific coverage of American ZIP codes for businesses focusing on the United States market. This database includes fundamental information about ZIP Codes, associated cities, and geographic coordinates.
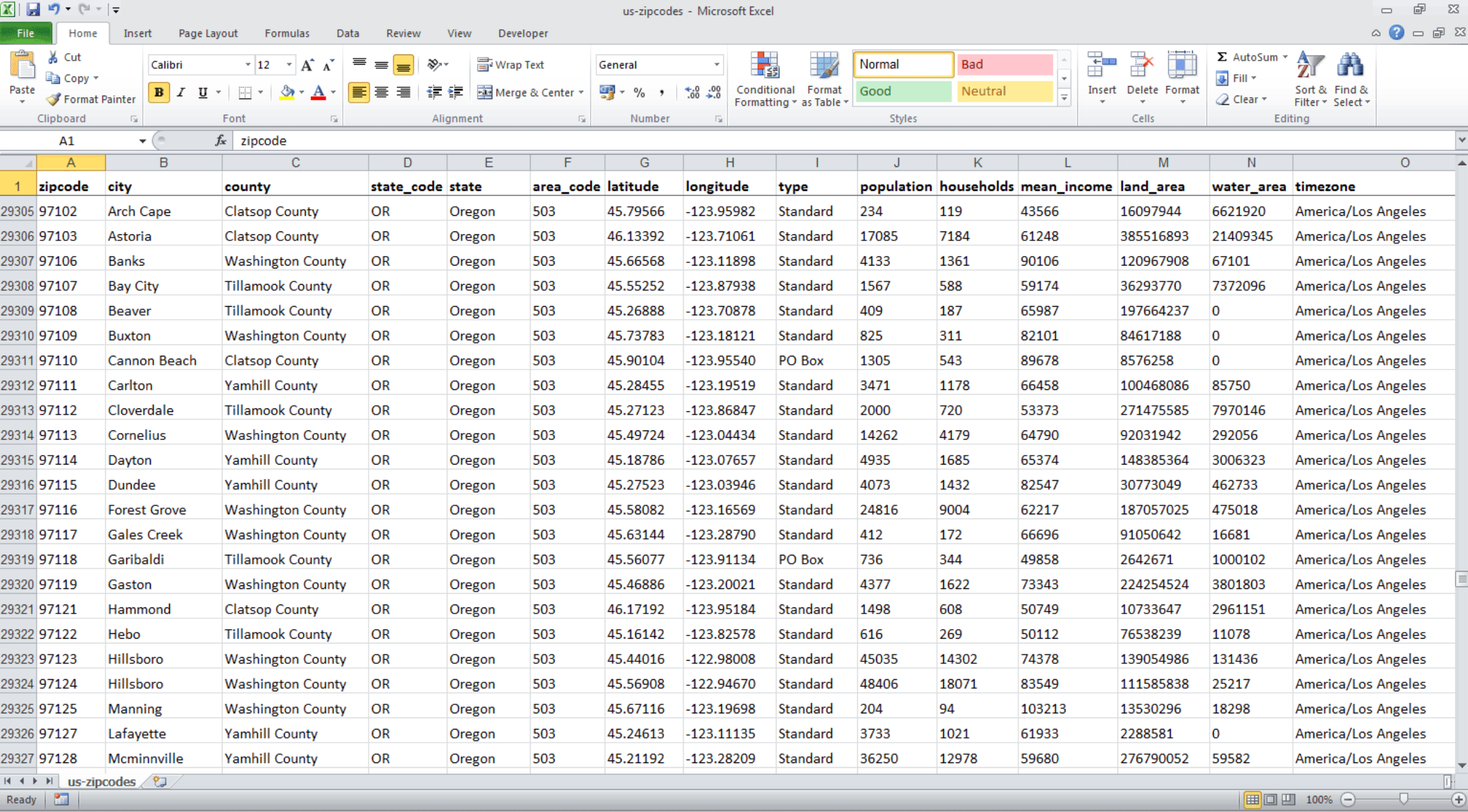
Strengths: The database stands out for its straightforward approach to U.S. ZIP code geography. It includes basic demographic data and boundary information for each ZIP Code, making it useful for initial market analysis.
Considerations:
- Coverage is limited to the United States and does not include international postal systems.
- Update frequency follows the project’s own release cycle and may not align with official USPS updates.
- Available attributes are limited to basic postal information.
- Format inconsistencies and the lack of standardized identifiers can complicate integration with other datasets.
Although the Uszipcode database supports many U.S.-based applications, its geographic scope makes it unsuitable for organizations operating internationally.
Worth keeping in mind: ZIP codes are designed for mail routing, not for defining administrative or geographic boundaries. As a result, they don’t always align with cities, counties, or census areas. This structural limitation can create difficulties when merging ZIP Code data with external datasets such as census records, customer databases, or mapping systems, particularly when consistent geographic identifiers are required.
| Feature | Details |
|---|---|
| Geographic Coverage | United States only |
| Update Frequency | Periodic updates |
| Data Validation | USPS-maintained |
| Postal Code Coverage | Complete U.S. coverage |
| Integration Capabilities | Database download |
| Best Use Case | U.S. address validation |
| Data Format | CSV/Database |
| Technical Expertise Required | Low |
| Additional Features | Basic demographic data |
| Considerations | U.S.-only coverage; pair with other datasets for international coverage |
HDX (Humanitarian Data Exchange)
About the provider: Humanitarian Data Exchange is a widely used open data platform that aggregates humanitarian and geographic datasets contributed by UN agencies, NGOs, governments, and research institutions. The platform offers administrative boundaries, population data, and crisis-related datasets at a global scale.
The platform prioritizes openness, humanitarian use cases, and ease of access, making it a popular choice for analysts and researchers working on global development and crisis response.

Strengths
- Wide range of humanitarian, demographic, and geographic datasets contributed by trusted institutions
- Standardized metadata and CKAN-based discovery that simplifies dataset lookup
- Multiple formats supported, including CSV, GeoJSON, and Shapefile
- Compatible with GIS tools, including QGIS, ArcGIS, and PostGIS
- Open licensing aligned with humanitarian data sharing principles
Considerations: HDX aggregates datasets from many contributing organizations, so structure, refresh frequency, and licensing terms vary across datasets. The platform is well-suited to humanitarian, development, and research workflows, and pairs well with curated datasets when an enterprise integration calls for uniform structure across all countries.
| Feature | Details |
|---|---|
| Geographic Coverage | Global (humanitarian focus) |
| Update Frequency | Crisis-driven updates |
| Data Validation | Contributor-led, with curation by HDX moderators |
| Postal Code Coverage | Varies by region |
| Integration Capabilities | API and bulk download |
| Best Use Case | Humanitarian operations |
| Data Format | Multiple standardized formats |
| Technical Expertise Required | Moderate |
| Additional Features | Humanitarian indicators |
| Considerations | Contributor frequency and structure vary across humanitarian programs |
Natural Earth Data
About the provider: Natural Earth Data is a widely used open-source geographic dataset that provides administrative boundaries, physical geography, and cultural landmarks at a global scale. It is designed primarily for cartographic applications and offers data in multiple resolutions (1:10m, 1:50m, and 1:110m scales).
The dataset prioritizes consistency, visual clarity, and ease of use, making it a popular choice for mapmakers and analysts who require a lightweight, general-purpose geographic dataset.

Strengths
- Consistent and well-structured datasets across administrative boundaries, coastlines, rivers, and populated places
- Standardized structure that simplifies integration into GIS and mapping workflows
- Multiple resolutions (low, medium, high) to support different levels of geographic detail
- Provided in user-friendly formats such as Shapefile and GeoJSON
- Compatible with GIS tools, including QGIS, ArcGIS, and PostGIS, with minimal preprocessing
- Public domain licensing with broad usage rights
- Includes complementary geographic features such as rivers, lakes, elevation contours, populated places, and urban areas
Natural Earth balances accuracy, completeness, and usability for cartographic and visualization purposes.
Considerations
- Administrative boundaries may not always be up-to-date or highly detailed compared to authoritative national sources
- The dataset prioritizes consistency over precision, which can result in simplified or outdated boundaries
- No postal code coverage, making it unsuitable for logistics, address validation, or postal-based demographic analysis without supplementation
- Potential spatial misalignment when combined with datasets derived from different projection systems or sources
- Updates follow Natural Earth’s own release schedule, meaning administrative changes may lag behind real-world developments
Organizations needing high-granularity administrative boundaries, postal code datasets, or frequent updates typically supplement Natural Earth with additional data sources.
| Feature | Details |
|---|---|
| Geographic Coverage | Global |
| Update Frequency | Periodic releases |
| Data Validation | Standardized cartographic dataset |
| Postal Code Coverage | No postal codes |
| Integration Capabilities | GIS-compatible formats (Shapefile, GeoJSON) |
| Best Use Case | Cartography and global geographic reference |
| Data Format | Shapefile, GeoJSON |
| Technical Expertise Required | Low |
| Additional Features | Physical geography, administrative boundaries |
| Considerations | Cartographic resolution; pair with other sources for postal codes or address data |
GADM (Database of Global Administrative Areas)
About the provider: GADM (Global Administrative Areas) is an open-access geographic database that provides detailed administrative boundary data for countries worldwide, covering multiple levels of administrative divisions from national to subnational scales.
Strengths: GADM stands out for its detailed hierarchical representation of administrative boundaries, from national borders down to local administrative units. This level of detail makes it particularly useful for:
- Choropleth mapping and regional visualization — Creating thematic maps that display data variations across administrative regions
- Reverse geocoding for administrative analysis — Determining which state, province, or municipality contains specific coordinates or addresses
- Multi-level geographic analysis — Analyzing data patterns at different administrative scales, from countries down to local districts
- Regulatory and compliance mapping — Understanding jurisdictional boundaries for legal, tax, or regulatory purposes
Considerations: GADM is distributed under an academic and research license. Commercial applications require separate licensing terms, which is worth checking against the intended use case.
While GADM offers reasonable quality administrative boundaries for exploratory or research use, its level of accuracy and ongoing maintenance may not meet higher-quality or production requirements.
Boundary geometries are usually simplified, and teams needing authoritative geometry typically reconcile GADM with national official sources.
Important Note: GADM’s main strength lies in its administrative boundary polygons rather than postal codes or address data. Organizations needing address validation or postal code lookup will pair GADM with another dataset that covers postal data.
| Feature | Details |
|---|---|
| Geographic Coverage | Global |
| Update Frequency | Periodic releases |
| Data Validation | Curated by researchers |
| Postal Code Coverage | None (administrative boundaries only) |
| Integration Capabilities | GIS-compatible formats (Shapefile, GeoJSON, etc.) |
| Best Use Case | Administrative boundary analysis |
| Data Format | Shapefile, GeoPackage, KMZ, R-raster |
| Technical Expertise Required | Moderate |
| Additional Features | Multi-level administrative hierarchies |
| Considerations | Academic / non-commercial license; commercial use requires separate licensing; no postal data |
Open-source Python libraries for location data
Python provides several libraries for handling location data, including postal codes and geographic queries. These tools support internal applications and data processing tasks, but coverage, data quality, and feature sets vary.
Pyzipcode: Simple but limited
Pyzipcode provides a straightforward way to handle ZIP Code operations in Python. It’s easy to implement, making it attractive for basic tasks like postal code validation and distance calculations within the U.S.
| Pros | Cons |
|---|---|
| Simple and lightweight | Limited to U.S. ZIP Codes |
| Quick setup for ZIP Code lookups and basic distance calculations | Lacks detailed demographic or geographic data |
| Not actively maintained |
Uszipcode: More features, similar constraints
Uszipcode builds on Pyzipcode by offering a more feature-rich database, including demographic and geographic details. It provides two database options: a simple version for basic lookups and a rich version with extended attributes.
| Pros | Cons |
|---|---|
| Includes demographic and geographic data | Still limited to U.S. ZIP Codes |
| Supports both simple and detailed database options | Requires database downloads, increasing setup complexity |
| Actively maintained and more flexible than Pyzipcode | Can be overkill for simple applications |
Geopy: Flexible geocoding but dependent on external APIs
Geopy allows developers to perform geocoding and reverse geocoding using various external providers, such as OpenStreetMap’s Nominatim, Google Maps, and Bing Maps. It is widely used for converting addresses into coordinates and vice versa.
| Pros | Cons |
|---|---|
| Supports multiple geocoding providers | Accuracy depends on the chosen geocoding provider |
| Works globally, unlike Pyzipcode and Uszipcode | Rate limits and API restrictions apply |
| Relatively easy to integrate into Python projects | Requires an internet connection to function |
Shapely: Advanced spatial analysis but no built-in data
Shapely is a powerful library for geometric operations, often used with other geospatial tools like GeoPandas and PostGIS. While it doesn’t provide location data, it helps process and analyze spatial relationships, such as determining whether a point is inside a polygon.
| Pros | Cons |
|---|---|
| Excellent for spatial operations and geometry processing | No built-in location or postal data |
| Works with other geospatial libraries like GeoPandas | It can have a learning curve for beginners |
| Supports advanced geographic calculations | Works best alongside a geospatial database like PostGIS |
Final considerations using open data from Python
Python offers powerful tools for working with location data, but each library has trade-offs. Pyzipcode and Uszipcode are helpful for simple U.S.-focused applications but fall short of global coverage. Geopy provides more flexibility but relies on third-party APIs, while Shapely is ideal for spatial analysis but lacks built-in postal data. Choosing the right tool depends on your project’s scale, scope, and requirements.
| Feature | Details |
|---|---|
| Geographic Coverage | Varies by the library, primarily US-focused, except Geopy |
| Update Frequency | – Pyzipcode: limited – Uszipcode: semi-regular – Geopy: API-dependent |
| Data Validation | – Pyzipcode: basic validation – Uszipcode, Geopy API-based: enhanced |
| Postal Code Coverage | – Pyzipcode: basic US – Uszipcode: comprehensive US – Geopy: API-dependent |
| Integration Capabilities | Python libraries, some require database downloads |
| Best Use Case | Python-based postal lookups, geocoding, spatial analysis |
| Data Format | – Pyzipcode, Uszipcode: Python objects – Geopy: API responses – Shapely: geometric data |
| Technical Expertise Required | Low to moderate, varies by library |
| Additional Features | – Geopy: Global geocoding – Uszipcode: US Demographics – Shapely: Spatial analysis |
| Considerations | – Pyzipcode: not actively maintained – Uszipcode: U.S.-only – Geopy: relies on external APIs |
Conclusion
Throughout this article, we’ve explored the landscape of open-source location databases, examining their features, strengths, and limitations. These resources represent remarkable achievements in collaborative data development and offer valuable options for many business applications.
Open-source location data can be valuable in specific scenarios:
- Initial exploratory analysis before committing to paid solutions
- Projects with limited budgets, especially non-profits and educational institutions
- Applications focusing on well-covered urban areas in developed regions
- Cases where community-updated information provides unique insights
- Situations where customization and control over data processing are paramount
It’s important to acknowledge that, depending on your use case and skill sets, using open-source data can either be the best, cheapest choice, or a tedious, expensive process. The quality and coverage vary significantly across different regions, and the technical expertise required to process, standardize, and maintain this data should not be underestimated.
A scenario we’ve witnessed multiple times involves organizations starting with open-source data and realizing months into development that the data quality or amount of work needed to polish it does not fit their business needs. This can result in significant delays and rework that could have been avoided with a more thorough initial assessment.
For businesses requiring consistent global coverage, standardized formats, regular updates, and reliable support, professional location databases may ultimately provide better long-term value despite the initial investment. These solutions can help overcome the limitations in coverage, structure, and maintenance that often challenge users of open-source data.
Whether you choose open-source or commercial location data depends on your specific business requirements, technical capabilities, budget constraints, and risk tolerance. By understanding the options presented in this article, you can make a more informed decision about the right approach for your location data strategy.
For organizations requiring reliable, standardized location data with global coverage and dedicated support, GeoPostcodes offers comprehensive solutions that may complement or enhance your existing data ecosystem. Browse GeoPostcodes database and download a free sample here.
FAQ
How can raw data like climate data or geology maps be used in a Geographic Information System?
A Geographic Information System (GIS) integrates various types of raw data, such as climate data and geology maps, to produce meaningful interactive maps. By loading this data into your mapping software, you can visualize environmental patterns and analyze spatial relationships. GIS tools transform complex datasets into actionable insights, accessible through easy-to-use web services and engaging interactive maps.
What open-source tools support LiDAR data and other GIS formats?
Open-source GIS tools like QGIS handle various datasets, including LiDAR data, standard GIS layers, and other GIS formats. They easily integrate lidar data alongside vector and raster datasets, allowing detailed analysis of geographic, demographic, and environmental information within a unified GIS platform.
Where can I find open-source data?
Find open-source location data through platforms like OpenStreetMap, Natural Earth, GADM, UN Open GIS, government portals (data.gov), Humanitarian Data Exchange, and NASA Earth Data. Universities, research institutions, and specialized repositories like OpenAddresses and GeoNames also offer free spatial datasets with varying coverage and accuracy.
Are there any open-source maps?
Yes, several robust open source maps exist. OpenStreetMap leads as a community-built global mapping platform. Alternatives include MapLibre GL, OpenLayers, Leaflet, and QGIS. These platforms provide customizable base maps, while Kepler.gl and D3.js offer visualization frameworks for creating interactive maps using open location data.
How to get geolocation data?
Obtaining geolocation data through geocoding APIs (Nominatim, Photon), government census databases, open repositories (GeoNames, OpenAddresses), mobile device GPS, IP address lookup services, specialized datasets from universities, and direct collection via GPS devices is an option. However, open source data has obvious limitations and can lead to financial and legal risks. For commercial applications, verifying quality and compliance with relevant privacy regulations is very important.
What commercial alternatives exist to open source location data?
GeoPostcodes provides a curated world postal code database with validated, standardized location data that’s more reliable than open source alternatives.
How can I access comprehensive US address data?
GeoPostcodes offers a master address list with extensive US coverage, providing more accurate data than typical open source solutions.
Is there a reliable source for international address data?
Yes, try GeoPostcodes’ address lookup for international addresses to test our data quality.
We provide validated address data for countries worldwide.



