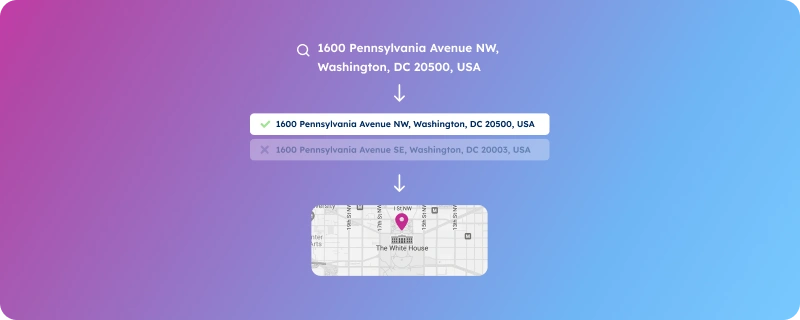

How do big companies like Amazon, Uber, or Airbnb easily connect with millions worldwide, dealing with various address formats, languages, and standards? They excel at matching addresses, which is key to their logistical success.
Address matching, also known as geocoding, is about assigning geographic coordinates to database addresses. This ensures that the physical location matches the address on file, which is crucial for product delivery and lead outreach.
You can check the step-by-step guide Geocoding: Building a Zip Code Coordinates Converter to learn how to use geocoding for your specific purposes.
Address matching faces numerous challenges, like typos, abbreviations, and changes in addresses due to new constructions or renaming. There are various advanced techniques to tackle these obstacles.
This article explains address matching, including its mechanics, application, and use cases for businesses. It also provides guidance on sourcing accurate location data for address matching, highlighting its essential role in global commerce.
We’ll also examine real examples of how companies Rosa and Monster utilize GeoPostcodes’ accurate address data in address matching.
💡 For over 15 years, we have created the most comprehensive world postal code database. Our location data is updated weekly, relying on more than 1,500 sources. Browse GeoPostcodes datasets and download a free sample here.
Understanding Address Matching
In this section, we explore how address matching works, outlining the key steps.
The Process of Address Matching
The address matching process unfolds in three phases: parsing, normalization, and matching. Here’s a closer examination of each phase.
Parsing
The initiation of the process, parsing, involves dissecting the address into its constituent elements such as street number, street name, city, state, and postal code.

This phase is crucial for isolating pertinent data from the address and setting the stage for subsequent steps. Various approaches, including rule-based parsing and machine learning, serve the parsing stage.
Rule-based parsing employs established rules and patterns for component extraction, whereas machine learning relies on trained algorithms to identify and categorize parts of the address.
Normalization
The next phase, normalization, is where address data undergoes modification and standardization.

This phase aims to rectify any discrepancies or ambiguities in the data. These discrepancies can be typographical errors, abbreviations, or incomplete entries.
The normalization stage aligns the information with recognized standards and formats. This includes adapting data to match formats sanctioned by authoritative bodies like the USPS or Canada Post.
Matching addresses
The final stage, matching, connects the address data with its physical location across multiple databases. This crucial step ensures the alignment of a physical location with its corresponding address record.

In this phase, utilizing methods like exact and fuzzy matching, we facilitate the association of addresses with locations, allowing for variances or similarities in the data when compared to official records.
These stages represent the core processes involved in address matching. Upcoming discussions will explore the varied techniques and strategies applied in address matching.
Methods for Address Matching
In the previous sections, we’ve covered the essence of address matching—its definition, importance, and mechanics.
Now, we focus on the various strategies employed in address matching, contrasting their pros and cons.
The spotlight falls on three principal techniques: exact matching, fuzzy logic address matching, and machine learning approaches.

Exact Matching Techniques
At their core, exact matching techniques represent the most rudimentary yet direct approach to address matching.
This process involves a side-by-side comparison of address data against authoritative databases, such as the USPS in the US, in search of a perfect match.
It is a traditional address matching, where an address is either an exact match or not a match.
A successful exact match assigns the physical location coordinates to the address data in question. The address data is flagged as invalid or incomplete when no match exists.
The process utilizes simple string comparison algorithms, where both addresses must be identical character by character to be considered a match.
Example Script (Python – Brute Force Approach):
def exact_match(input_address, database):
for record in database:
if input_address.strip().lower() == record.strip().lower():
return True, record # Return True and the matching record
return False, None # No match foundBrute Force Approach:
In this script, the term “brute force” refers to a straightforward method of comparing every input address against every record in the database sequentially.
Limitations: While simple, this approach can be inefficient for large databases as it checks each record one by one.
Pros:
- Simplicity and quick implementation: Exact matching techniques are straightforward to implement and do not require extensive algorithm development or computational resources
- High accuracy and reliability: They offer precise results, assuming the address is present in the authoritative database, without the need for complex algorithms
- Efficiency: Exact matching techniques can quickly process address data, making them suitable for applications where speed is crucial
Cons:
- They struggle to handle variations, errors, or inconsistencies within address data
- These techniques face challenges with diverse address formats, standards, and conventions across different sources and nations
- As a result, they may overlook legitimate addresses that have minor discrepancies from database records
Fuzzy Logic Address Matching
Fuzzy logic allows you to set rules for address standardization, correcting address information like street names to match with greater accuracy.
This flexibility allows for automatic corrections of addresses by leveraging sophisticated algorithms, often AI-driven, to navigate typos, variations, and inconsistencies within address data.
It accommodates differing address formats and standards across jurisdictions, assigning a similarity score to each address and comparing them with authoritative databases to find the closest match.
It often uses algorithms like Levenshtein distance to quantify similarities between two strings, allowing for differences up to a certain threshold.
Example Script: Python – Fuzzy Matching with Levenshtein Distance
from difflib import SequenceMatcher
def fuzzy_match(input_address, database, threshold=0.8):
for record in database:
similarity = SequenceMatcher(None, input_address.lower(), record.lower()).ratio()
if similarity >= threshold:
return True, record # Return True and the closest matching record
return False, None # No sufficiently close match foundLevenshtein distance measures the similarity between two strings by calculating the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one string into the other.
By using Levenshtein distance, this script can identify matches even with minor differences or misspellings.
Pros:
- Accuracy and completeness: Fuzzy logic enhances the accuracy and completeness of address databases by correcting errors and increasing match rates, ensuring more reliable results
- Error correction: It automatically corrects erroneous inputs, reducing inaccuracies in address matching and improving data quality
Cons:
- Complexity and computational requirements: Fuzzy address matching algorithms are more complex and demand more computational power than exact matching techniques, potentially requiring greater resources for implementation and maintenance
- Variable accuracy: It doesn’t guarantee the same level of accuracy and reliability, as it may align addresses not verified by authoritative databases or overlook addresses with minor discrepancies from the database entries
Machine Learning Approaches
These approaches, at the forefront of address matching technology, use data-trained algorithms to create self-improving models.
Machine learning models for address matching learn from large datasets of addresses and their correct formats to predict the most likely correct version of new, unseen addresses.
These models can predict outcomes and organize information autonomously, reducing the need for manual oversight.
Example Code: Python – Supervised Learning with RandomForest
from sklearn.ensemble import RandomForestClassifier
def train_address_matcher(features, labels):
model = RandomForestClassifier()
model.fit(features, labels)
return model
def predict_address(model, new_address):
return model.predict([new_address])In this example, RandomForestClassifier is a supervised learning algorithm that learns from labeled training data to classify new addresses.
Training and Prediction: The train_address_matcher function trains the model with features (e.g., address attributes) and corresponding labels, while the predict_address function predicts the label (e.g., correct address format) for a new address.
Machine learning in address matching encompasses supervised, unsupervised, and reinforcement learning, each with distinct functions.
Supervised learning
Supervised learning operates on labeled datasets to enhance address matching by predicting coordinates for new addresses based on training data.
Unsupervised learning
Unsupervised learning groups addresses based on common features, identifying similarity clusters without predefined categories.
Reinforcement learning
Reinforcement learning adopts a learn-by-doing approach, refining address matching capabilities through trial and error, optimizing for the best outcomes guided by reward signals.
Pros:
- Adaptability and learning capacity: Machine learning excels in adapting to new data and learning from it over time, enabling it to handle complex and dynamic address data with precision
- Evolving accuracy: With continued training, machine learning models can improve their accuracy over time, ensuring that address matching results become increasingly precise and reliable
Cons:
- Deployment challenges: Implementing machine learning for address matching requires specialized knowledge for design, implementation, and sustained operation, as well as substantial data processing capacities
- Accuracy hurdles: Factors like data noise, biases, or overfitting can undermine the accuracy of machine learning models, highlighting the need for careful consideration and fine-tuning to maintain optimal performance
Tips and Tricks to perform address matching
Data Cleaning
Address matching algorithms need to handle variations and inconsistencies in unclean data to accurately match addresses across datasets.
Here’s a comparison of two addresses with clean and unclean address elements, which may include input errors:

In the clean address data:
- The street address is standardized without additional characters or abbreviations.
- The city name is spelled out completely.
- The state abbreviation is standardized.
- The postal code is in a standard format.
In the unclean address data:
- The street address contains a period after “St.” and lacks a suite number.
- The city name is abbreviated.
- The postal code includes an extended ZIP+4 code.
We need to preprocess address data to standardize formats, remove noise, and correct errors before matching:
def preprocess_address(address):
# Standardize address format, remove noise, correct errors
# Example: Convert to lowercase, remove special characters
return address.lower().replace('-', ' ').replace(',', '')Hybrid Address Matching
1. Exact Matching
- Use exact matching to quickly identify addresses that have an exact match in the database.
- This helps capture accurate matches for addresses that are already standardized and present in the database.
def exact_match(input_address, database):
for record in database:
if input_address.strip().lower() == record.strip().lower():
return True, record # Return True and the matching record
return False, None # No match found2. Fuzzy Address Matching Algorithm
- Apply fuzzy logic matching to handle variations, typos, and minor discrepancies in addresses.
- This step improves matching accuracy by allowing for partial matches and similarity scoring.
from difflib import SequenceMatcher
def fuzzy_match(input_address, database, threshold=0.8):
for record in database:
similarity = SequenceMatcher(None, input_address.lower(), record.lower()).ratio()
if similarity >= threshold:
return True, record # Return True and the closest matching record
return False, None # No sufficiently close match found3. Machine Learning-based Matching
- Utilize machine learning models trained on labeled address data to predict matches for new, unseen addresses.
- Supervised learning algorithms, such as RandomForestClassifier, can be used for classification tasks.
from sklearn.ensemble import RandomForestClassifier
def train_address_matcher(features, labels):
model = RandomForestClassifier()
model.fit(features, labels)
return model
def predict_address(model, new_address):
return model.predict([new_address])4. Hybrid Approach Integration
- Combine exact matching, fuzzy logic matching, and machine learning-based matching techniques into a unified matching function.
- Implement logic to prioritize and combine the results from each matching technique to provide the most accurate match.
def hybrid_match_address(input_address, database, model, threshold=0.8):
# Exact matching
exact_matched, exact_record = exact_match(input_address, database)
# Fuzzy logic matching
fuzzy_matched, fuzzy_record = fuzzy_match(input_address, database, threshold)
# Machine learning-based matching
ml_prediction = predict_address(model, input_address)
# Combine results based on priority or confidence levels
if exact_matched:
return True, exact_record
elif fuzzy_matched:
return True, fuzzy_record
elif ml_prediction:
return True, ml_prediction
else:
return False, None5. Usage
- Use the hybrid_match_address function to match input addresses against the database, leveraging the combined strengths of exact matching, fuzzy logic matching, and machine learning-based matching.
# Example usage
input_address = "123 Main St, Springfield"
database = ["123 Main St, Springfield, USA", "456 Elm St, Springfield, USA", "124 Main St, Springfield, USA"]
model = train_address_matcher(features, labels)
matched, matched_record = hybrid_match_address(input_address, database, model)
if matched:
print("Match found:", matched_record)
else:
print("No match found.")Performance Optimization Example: Indexing and Caching
1. Indexing
- Create an index for the address database to facilitate faster search operations.
- In this example, we’ll use a Python dictionary to create an index based on a specific attribute of the address (e.g., postal code).
def create_index(database, index_key='postal_code'):
index = {}
for record in database:
key = record[index_key]
if key in index:
index[key].append(record)
else:
index[key] = [record]
return index
# Example usage
address_database = [
{'street': '123 Main St', 'city': 'Springfield', 'postal_code': '12345'},
{'street': '456 Elm St', 'city': 'Springfield', 'postal_code': '12345'},
{'street': '789 Oak St', 'city': 'Springfield', 'postal_code': '67890'}
]
address_index = create_index(address_database, index_key='postal_code')2. Caching
- Implement a caching mechanism to store recently accessed or frequently used address records in memory.
- This reduces the need to repeatedly query the database for the same records, improving overall performance.
class AddressCache:
def __init__(self, max_cache_size=1000):
self.cache = {}
self.max_cache_size = max_cache_size
def add_to_cache(self, key, record):
if len(self.cache) >= self.max_cache_size:
# Remove the oldest entry from the cache if it exceeds the maximum size
self.cache.popitem(last=False)
self.cache[key] = record
def get_from_cache(self, key):
return self.cache.get(key)
# Example usage
cache = AddressCache(max_cache_size=1000)
# Add address record to cache
cache.add_to_cache('12345', {'street': '123 Main St', 'city': 'Springfield', 'postal_code': '12345'})
# Retrieve address record from cache
cached_record = cache.get_from_cache('12345')3. Address Matching with Indexing and Caching
- Utilize the index and cache to optimize the address matching process.
- Before performing a search in the database, check if the address record is available in the cache. If not, use the index to quickly locate relevant records.
def match_address_with_index_and_cache(input_address, address_index, cache):
# Extract relevant attribute for indexing (e.g., postal code)
index_key = extract_index_key(input_address)
# Check if record is in cache
cached_record = cache.get_from_cache(index_key)
if cached_record:
return True, cached_record
# If not in cache, use index to find relevant records
matching_records = address_index.get(index_key, [])
for record in matching_records:
# Address matching logic here
if is_address_match(input_address, record):
# Add matched record to cache for future use
cache.add_to_cache(index_key, record)
return True, record
return False, None
# Example usage
input_address = "123 Main St, Springfield, 12345"
matched, matched_record = match_address_with_index_and_cache(input_address, address_index, cache)By implementing indexing and caching mechanisms, you can significantly improve the performance of address matching, especially for large datasets, by reducing the time required for search operations and minimizing database access.
Feedback Loops:
Incorporate user feedback mechanisms to continuously improve matching accuracy over time.
def update_database(input_address, matched_record):
# Incorporate user feedback to update database with corrected address
pass # Placeholder for database update implementationError Handling:
Implement mechanisms to handle edge cases, such as missing or incomplete addresses, gracefully.
def match_address(input_address, database):
if not input_address:
raise ValueError("Input address is missing or empty")
for record in database:
if not record:
continue # Skip empty database records
# Address matching logic here
return False, None # No match foundIn this example, we raise a ValueError if the input address is missing or empty. We also skip empty records in the database to avoid errors during matching.
Scalability:
Design systems with scalability in mind to handle increasing volumes of address data efficiently.
from multiprocessing import Pool
def parallel_match_address(input_addresses, database):
with Pool() as pool:
results = pool.map(match_address, input_addresses)
return resultsIn this example, we use multiprocessing to parallelize address matching across multiple CPU cores, improving performance for large datasets.
Validation:
Validate matched addresses against authoritative sources or human input to ensure correctness.
def validate_address(matched_address):
if not matched_address:
return False
# Validate against authoritative source or human input
return TrueIn this example, we validate matched addresses against an authoritative source or human input to ensure accuracy and correctness.
Documentation:
Document algorithms, parameters, and decision processes to facilitate maintenance and knowledge transfer.
"""
This function matches input addresses with records in the database.
Parameters:
- input_address (str): The address to be matched.
- database (list): A list of address records for comparison.
Returns:
- bool: True if a match is found, False otherwise.
- str: The matching record if a match is found, None otherwise.
"""
def match_address(input_address, database):
# Address matching logic here
passIn this example, we provide detailed documentation for the match_address function, including parameters, return values, and a brief description of its functionality. This documentation helps developers understand and use the function effectively.
Finding Accurate and Up-to-Date Data for Address Matches
In earlier discussions, we covered the essence of address matching, its significance, and various methodologies for implementation.
This segment delves into sourcing precise and current data for address matching and underscores why this is pivotal for the triumphant execution of your address matching venture.
Address matching fundamentally involves contrasting your address compilations with a definitive database that catalogs addresses alongside their geographical coordinates.
Databases vary significantly in accuracy, completeness, and currency. This variability can critically impact the dependability and effectiveness of your address matching endeavors.
To mitigate these issues, we should select a database characterized by:
- Adequate coverage across the necessary countries and territories for your operations
- Regular and systematic updates to mirror the dynamic nature of address information
- Authentication and corroboration by reputable entities, such as postal services or governmental bodies
- Consistency with regional formatting and standardization requisites
- Geocoding capabilities, providing precise geographical coordinates for addresses
While GeoPostcodes is a premium option for address matching data, alternative free tools exist, like Google Places or OpenStreetMaps.
However, these are not accurate, comprehensive, or timely, as they lean on crowd-sourced data and estimations.
These alternatives may also fall short of covering all required territories or offering the desired functionalities and features.
💡 Our location data is updated weekly, relying on more than 1,500 sources. Browse GeoPostcodes datasets and check out our worldwide address database here.
Step-by-Step Guide to Match Addresses
This section aims to provide a step-by-step tutorial on integrating address matching into your enterprise, focusing on leveraging an API or web service.
We’ll explore the advantages and challenges of using these technologies for address matching and offer insights on selecting the most suitable option for your needs.
An API or web service serves as a software intermediary, allowing interaction with another software system via the Internet.
Outlined below are the essential steps to employ when integrating an API or web service for address matching:
Selection of an API or Web Service:
Identifying the right API or web service for address matching involves evaluating several key factors, including service coverage, accuracy, processing speed, costs, security measures, and reliability.
It is also critical to examine the service’s compatibility with various address formats, standards, and conventions, its address matching methodologies, and the type of feedback it generates.
To make an informed decision, consider comparing various APIs and web services based on online reviews, ratings, and user testimonials or by taking advantage of a free trial or demonstration provided by the service.
System Integration:
Upon selecting your preferred API or web service, the next step involves integrating it into your existing system infrastructure, such as a website, application, or database.
This process typically requires registering for an account, securing an API key or token, and adhering to the service’s provided documentation and guidelines.
Additionally, customization of the service settings and parameters may be necessary, including input/output format adjustments, similarity thresholds, and error management protocols.
To ensure smooth service integration and operational functionality, consider conducting tests with sample data or utilizing the service’s provided dashboard or console.
Submitting Address Data:
With the API or web service successfully integrated, you can now submit your address data for matching.
This process generally involves dispatching an HTTP request to the service’s endpoint, including your address data as a parameter, and awaiting the service’s response.
Ideally, the response should include the validated, standardized, and correlated address information, along with geographical location coordinates, a similarity score, and any pertinent errors or warnings.
The received response data can be stored, displayed, or utilized.
By following these steps, you can effectively utilize an API or web service for address matching, reaping significant benefits.
These include saving time and resources, improving data quality and consistency, enhancing customer satisfaction and loyalty, and boosting operational efficiency and profitability.
Nonetheless, potential challenges may arise, including the selection of a reliable and reputable service provider, data privacy and security assurance, managing network and service disruptions, and adhering to applicable data regulations and standards.
It is, therefore, essential to thoroughly assess your needs and options before committing to and employing an API or web service for address matching purposes.
How businesses use Address Matching
This section focuses on practical applications, explaining why and how businesses leverage address matching to their benefit.
We’ll also examine case studies featuring two GeoPostcodes clients, Rosa and Monster.
Address matching serves various purposes for businesses, such as:
- Boosting customer satisfaction and loyalty by ensuring accurate delivery of products or services, hence minimizing errors, delays, and returns
- Augmenting data quality and uniformity by validating, standardizing, and synchronizing addresses across diverse databases, sources, and systems
- Enhancing operational efficiency and profitability through the optimization of routes, logistics, and distribution networks, thus cutting costs and diminishing waste
- Facilitating data analysis and visualization through geocoding addresses and correlating them with physical locations to unveil patterns, trends, and insights
- Adhering to data regulations and standards by conforming to local address formatting, validation, and matching requirements
Rosa
Rosa, a Belgian enterprise, bridges the gap between patients and health professionals. On Rosa’s platform, patients can search for health professionals by entering city names or postal codes. Utilizing the selected city’s coordinates, Rosa can then present a curated list of health professionals that align with the patient’s search criteria within Belgium.
With GeoPostcodes’ data at their disposal, Rosa is able to:
- Generate more precise matches based on accurate city coordinates
- Significantly enhance the user experience on their website by presenting address results in Belgium’s three official languages: French, Dutch, and German
Dive into Rosa’s use case here.
Monster
Monster, renowned globally for fostering connections between job seekers and employers for over a quarter century, relies on precise location data to effectively align positions and candidates.
The precision and reliability of postal code data are paramount in their operations.
By leveraging GeoPostcodes’ data, Monster can:
- Access a complete, precise, and cost-efficient location database that negates the need for extensive maintenance resources
- Offer meticulously accurate address matching for both candidates and employers through the use of GeoPostcodes’ latitude and longitude coordinates, thus providing exceptionally accurate results
These instances underscore just a fraction of the ways in which businesses employ address matching and the pivotal role that accurate data plays in achieving their operational objectives.
Dive into Monster’s use case here.
Conclusion
In this article, we’ve clarified the significance of address matching, delved into its methodology, and explored diverse strategies for its execution.
We’ve also underscored the crucial role of reliable, up-to-date data for address matching applications and how businesses leverage these functionalities to reap multiple benefits.
We maintain a global list of accurate address data, covering coordinates, administrative divisions, geocodes, and time zones. Our data is regularly updated, with advanced processing pipelines tailored to each country/’s specific requirements.
For instance, 99.6% of our postal codes have accurate coordinates, while the remaining 0.4% inherit coordinates from their respective administrative divisions.
We thrive on solving these challenges and would be delighted to assist you. Reach out to us for more information, or explore our data directly on our website.
FAQ
What is address matching in fuzzy logic?
Address matching in fuzzy logic refers to the process of identifying and associating different representations of the same physical address using approximate matching techniques.
This approach handles minor discrepancies in data entries due to typographical errors, different address formats, or incomplete information.
Fuzzy logic enhances the accuracy of address matching by considering the likelihood of similarity between different address components rather than seeking an exact match.
How to Ensure a correct address match?
Address matching utilizes algorithms to compare address strings against authoritative databases or reference datasets, such as the Postcode Address File (PAF).
By analyzing address components and patterns, address matching algorithms identify correct matches by comparing the entered address with validated records, ensuring accuracy and completeness.
What is the Python package for address matching?
The Python package commonly used for address matching is usaddress.
This package utilizes natural language processing techniques to parse and categorize address components, making it easier to match and standardize addresses across datasets. usaddress is effective in handling various address formats found in U.S.-based data.
What does fuzzy matching aim to address?
Fuzzy matching aims to address the issue of data discrepancies in text records by allowing for partial matches instead of exact ones.
This technique is particularly useful in managing data that may contain errors, variations in spellings, synonyms, or incomplete information.
Fuzzy matching is widely applied in data cleaning, information retrieval, and merging databases where exact matches are not possible due to inconsistencies in data entry or expression.
What is the address matching system API?
An address matching system API is a software interface that allows applications to access address matching services.
These APIs facilitate the validation, standardization, and correction of postal addresses within an application.
By integrating an address matching API, developers can ensure that address data is accurate and formatted correctly, which is crucial for logistics, customer data management, and location-based services.
What database helps with address matching?
GeoPostcodes’ global address validation database provides standardized data essential for accurate address matching.



