

Have you ever worked on global data analysis? If so, you might have encountered some challenges along the way. Did you face issues sourcing international data, matching datasets with different standards, or finding the correct scale for your analysis?
These problems are common in spatial analysis, especially when dealing with multiple countries and cultures. Finding common ground can be daunting and time-consuming. The key lies in using a familiar scale for easy comparison and comprehension.
Zip codes frequently serve as common denominators, as they are present in almost 200 countries and refer to relatively small areas that facilitate accurate and accessible information.
Besides data analysis, zip codes are critical for a range of operations: properly capturing the delivery address for e-commerce, keeping your customers’ contacts for legal obligations or taxes, etc. It hence becomes necessary to rely on a global postcode database.
We must combine multiple datasets into one coherent and homogeneous model to build such international data. Different countries use different formats for their postal data, adding complexity to the aggregation process.
This article will discuss the main challenges of combining zip code data. By the end, you’ll better grasp the work required and some valuable tips to handle postal data effectively.
Why do you need a unified zip code data structure?
Zip codes share a sense of familiarity due to similarities in their representations. All zip codes are alphanumeric characters representing a more or less granular area. These codes were originally developed by postal organizations for mail and parcel delivery, a purpose they still serve.
They have also become an essential part of many legal documents. They also form valuable reference data for spatial analysis and all business operations requiring accurate location data.
Usually more granular than zip codes, addresses offer precise location data, enabling the pinpointing of specific points of interest. Both zip codes and addresses can take various forms like points, polygons, or tables, offering versatility to support analysis in diverse business fields.
Consistent data across countries is crucial for businesses expanding into new markets or seeking effective international assets management. When companies venture into unfamiliar territories, a unified database of international addresses becomes vital. This standardized data ensures accurate customer insights, streamlined supply chain operations, enhanced customer experiences, and simplified compliance with regulations.
Let’s look at some possible use cases for this data.
Market research: Track consumer behavior, identify market trends, and assess the potential for new products or services. Businesses can use it to make informed marketing and product development decisions. Another example is tracking the sales of a particular product across different countries and sub-regions.
Fraud detection: Identify irregularities or anomalies that may signal fraudulent activity by analyzing transaction patterns associated with different zip codes. Unusual patterns, such as transactions originating from foreign zip codes or sudden shifts in purchasing behavior across international areas, can raise red flags. Employing geolocation data can help pinpoint the actual location of transactions, allowing for quick legitimacy assessment.
Territory Mapping: Zip codes serve as powerful tools for mapping territories due to their hierarchical and geographical nature. Businesses and organizations can define and visualize distinct areas by aggregating zip codes belonging to these areas and performing activities such as sales territory mapping.
Which tools do you need to build a standardized zip code dataset?
In this guide, we’ll illustrate various aspects of the process, offering advice on what we believe to be efficient solutions. You will learn to leverage your existing tools and expertise to build a standardized zip code dataset. While plenty of data aggregation tools exist, some stand out because they can significantly speed up the process. Here are two solutions worth considering:
- PostgreSQL / PostGIS: Although Graph databases have advantages, storing your postal data in a relational database is a natural choice. Utilizing the Pl/pgSQL scripting language enables you to automate the aggregation process with excellent performance, especially on large datasets. Additionally, the PostGIS extension facilitates handling coordinates and spatial representations of zip codes. Mastering all shapes of zip codes is truly comfortable when you have various data formats and analyses to process. You can learn how to build your zip code polygon database here.
- Python (Pandas / Geopandas, PolarRS): Python reigns as the go-to language for data processing. Pandas and Geopandas offer easy aggregation and manipulation of your postal datasets, as does PolarRS. Although this approach provides the simplest means to handle postal data, it may become tedious with large datasets in Pandas.
In other words, a combination of a database and a data-processing solution is our preferred approach. Now, let’s dive into the guide.
We will go through 7 challenges you will encounter if you plan to combine postal data internationally:
- Find and catalog data sources
- Design your data model
- Pre-process your data source and extract relevant information
- Link to administrative divisions
- Geocode your new data
- Link postal data with other standards
- Assess your aggregated data quality
1. Find the right data sources
The first challenge is identifying and gathering diverse data sources across governmental databases, commercial providers, and open-data platforms. Several criteria come into play to define a “good” postal data source for aggregation :
A) Reliable Source: Zip codes result from practical and legal decisions by postal operators and governments. You could run into issues later if your source doesn’t gather official data.
B) Up-to-date Source: Postal organizations regularly create, replace, or remove zip codes. Local and governmental sources are well-informed about changes, but international sources may face challenges staying updated.
C) Accurate Data: Seek sources with technically accurate data, including valid coordinates and correct attributes. This aligns with reliability and up-to-date criteria, highlighting the source’s expertise in data creation.
D) Easy-to-Use Data Model: Opt for a source with a straightforward and easily manageable data model to avoid mistakes and save time. Complex data models require additional time to understand and process.
Following those criteria, the best sources generally are governmental and national postal services. They are accurate, up-to-date, and authoritative. For example, the National Address Database from France is a “good” source because it’s up-to-date, strongly reliable, and the only postal database recognized by French institutions.
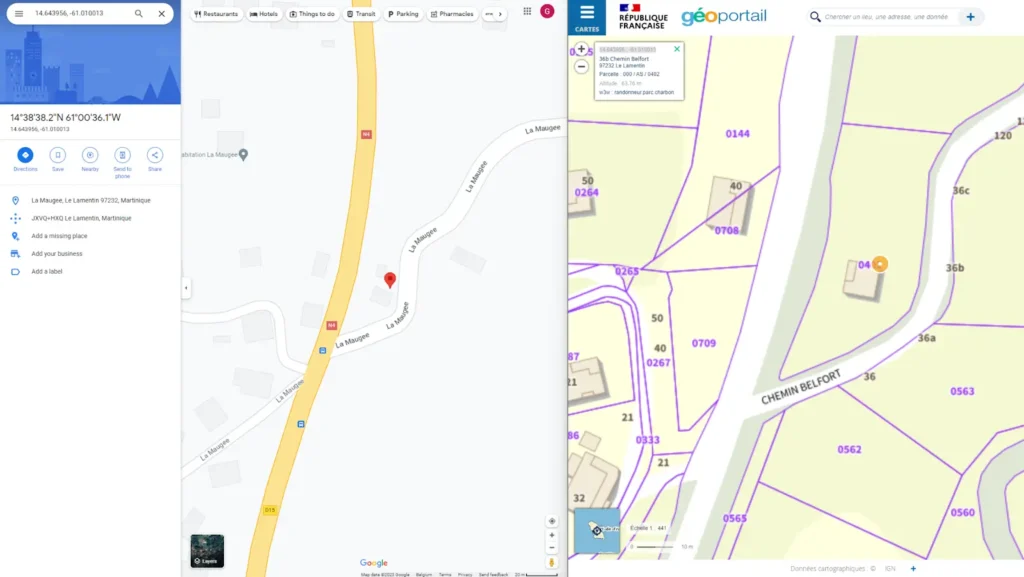
Nevertheless, these sources have a main drawback: they give only one country/ and are strongly focused on local use. It implies that data formats, structure, and content will only work with national standards. Therefore, we must adapt our extraction process to gather these local data in an international context. Let’s start with the data structure.
2. Design your data model
The significance of a well-defined data model in the postal data aggregation process cannot be overstated. You need to define a data model that will support your aggregation. In other words, you will need to think about the rows of your new table and their constraints.
A thoughtfully designed data model streamlines the aggregation process, simplifying data extraction, transformation, and loading procedures. Regarding the previous part, we will only use sources related to one country/ (and maybe their dependencies). It implies these datasets will have constraints set to cater to local use cases. To obtain a coherent aggregated dataset, we must design a model that can take account of local constraints in a global context.
In other words, the main challenge here is to design a generic data model to aggregate our local postal data into an international framework.
We suggest defining a common hierarchical structure for all countries in the world. It does not matter if administrative divisions are called States in some countries, Provinces in others, or Prefectures in others. What is important is that you can encode all countries in a common system. It is common to use hierarchical systems and to set a maximum depth (GeoPostcodes uses up to 6 layers within each country/, OpenStreetMap 11, yet the country/ is already at level 4 in OpenStreetMap) to avoid over-complexifying your whole model to accommodate all exceptions.
Zip codes can then be attached to some of those levels, and you can then transform zip data into administrative division aggregations.
3. Pre-process your data source and extract relevant information
Address formats differ from country/ to country\/. You can find a few examples in the figure below. For further information, please refer to this article about international address formats.

Given that address formats vary, it is no surprise that address data sources are structured differently from country/ to country/: not only the order into which data is provided but also the presence of some fields (e.g., administrative hierarchy, statistical codes) and even data models differ (some countries export all data in a single file, others in a set of files, for instance, one for postal codes, another one for the administrative hierarchy).
4. Link to administrative divisions
It is convenient to link postal codes and cities to the administrative divisions they belong to. Even when it is not a required part to properly format the address, it can serve to aggregate the data (e.g., useful for marketing projects) but also filter it (e.g., e-commerce form first asking for the province to narrow down the possible postal codes) or identifying the data (it is frequent localities share the same name).
Using administrative divisions can help your users identify the proper one if they don’t know the postal code.
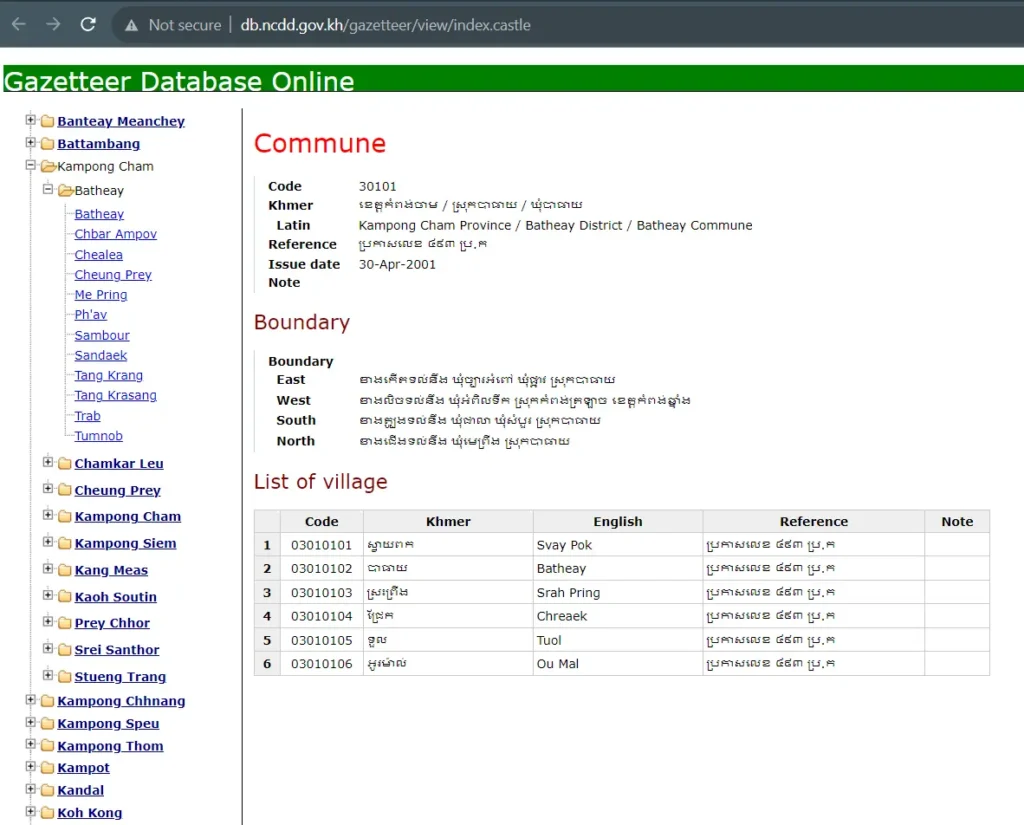
It’s usually possible to find public data. Many countries release administrative data as open data (sometimes, the source of hierarchical administrative divisions is called a gazetteer, as illustrated below for Cambodia). It frequently includes a unique, hierarchical code maintained by the National Office of Statistics.
You may have access to such codes in your postal source as well. Otherwise, you will need to match the names of administrative divisions (if available in your postal source) or coordinates, which brings its challenges (you need good coordinates for the postal source, as explained below, but also reliable polygons for the administrative divisions).
5. Geocode your new data
If the original datasets do not include geographic coordinates (latitude and longitude), you should try to add this spatial information to your data. Read our geocoding guide on how to build a zip code to coordinates converter. Geocoding will enable you to visualize the data on a map accurately, for example, in QGIS or ArcGIS Pro.
Good coordinates are critical for certain applications even when mapping is unnecessary, for instance, when computing distance to estimate shipping costs. It can also be useful while building the address database, enabling you to check your data quality.
You will have to turn to other sources of information to geocode that does not readily come with coordinates from your postal/address sources. Commercial geocoding services (e.g., Google API) and open data (e.g., OpenStreetMap, Geonames, Wikidata) exist. It is challenging to match the data, though.
First, names could be written differently (abbreviations, language/script, capitalization). Second, you must ensure you uniquely identify your objects: having multiple cities sharing the same name in a given country/ is common. If your geolocalized source does not contain reliable postal codes, which is likely the best option is to leverage the administrative hierarchy to ensure you’re matching places from the same area.
You can do that either through geospatial queries (if you have the polygons of the administrative divisions) or by comparing the administrative hierarchies from both sources.
More details on geocoding a zip code database can be found in this article.
6. Link ZIP codes with other standards
Numerous location codes offer a unique referential to identify places or administrative divisions. They are called “geocodes”. The most popular ones are ISO3166-2, FIPS, HASC, NUTS, and UNLOCODES for the Transportation sector.
Such codes offer advantages when matching datasets, as unique identifiers avoid string-matching challenges (capitalization, punctuation, abbreviations, language or script, etc.).
Yet, string matching is again one of the best options to include geocodes in your postal database so it can later be easily linked to other data. Nevertheless, as we just mentioned, it is not straightforward: you will need to analyze and convert the strings to overcome some difficulties (normalization of names, different scripts, unique identification).
The other option to match your postal data to international geocodes is to find reliable maps of such geocodes (NUTS does produce some maps along their tabular, hierarchical data, as shown in the figure below).
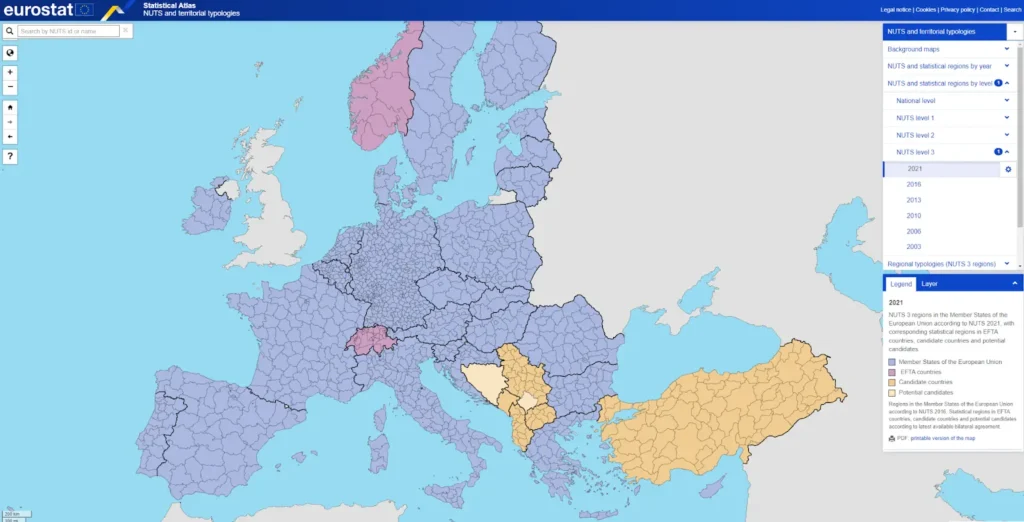
Please note that such international sources are frequently slow to update their data and react to local changes. This can cause mismatches between your data sources. For instance, it took three years for ISO to produce codes for the Algeria provinces created in 2025, and HASC is not maintained anymore.
7. Assess your aggregated data quality and consistency
Maintaining high-quality data is critical for your data to be useful on a large scale. Zip codes, cities, and administrative divisions evolve, so you must frequently update your data to stay relevant. This includes following many sources, from postal operators to statistical offices or international geocodes (ISO is late in publishing changes, but it has the advantage of gathering them from one source).
Besides up-to-dateness, there are also consistency aspects to consider. One dimension we have already mentioned is string normalization. You must choose one format (capitalization, punctuation, abbreviations) first, stick to it, and test afterward if all your names respect that format. The same applies to zip codes; you must check all codes from one country/ to respect that country/’s defined format.
You must also ensure you have linked your postal codes to the correct cities (in the proper administrative divisions). As zips usually follow a hierarchy (the first characters denote a broad region, then the following characters identify a delivery area within it), a basic test is to verify that the zip prefixes match what you expect for every high-level administrative division. A more advanced test involves the coordinates of the towns and their related zip codes.
You shouldn’t have postal codes linked to localities that are far away (everything is relative, though; for instance, wide areas in Canada belong to a single locality, so postal codes can be further away than in Singapore). Note that long connections between zip codes and localities can also mean you have wrong coordinates for your entities, something you can check by trying to match your localities with open data sources (e.g., OpenStreetMap).
Other factors involve missing data. You may want to ensure all localities are linked to at least one postal code (attention, it’s not the case in all countries), all your localities belong to administrative divisions, and the other way around, all your administrative divisions include at least one locality. There are numerous data quality tests to set up to ensure your data is consistent, and as you can imagine, solving issues is also time-consuming.
Conclusion
This article lists the main challenges to overcome when aggregating postal data internationally. The first obstacle is to find good source data. As reliable data usually have limited scope (geography and features), there are numerous subsequent challenges in bringing data sources together: designing an efficient data model (generic yet simple); dealing with various languages, scripts, and conventions; standardizing names; matching different sources to enrich the data (administrative divisions, geocodes, coordinates, time zones, etc.). These operations can be tedious and error-prone, so you must set up a range of data quality tests to ensure your data is valid and coherent.
How Geopostcodes can help
This is hard enough for a couple of countries. If you need quality data for several countries, outsourcing those efforts to a trusty data provider will save you both time and money. At Geopostcodes, we have already set up all these processes to aggregate postal data for more than ten years. We ingest over 1500 data sources to build our worldwide databases.
All the data is cleaned, normalized, and pushed to a unified data model. We keep track of the changes on the postal and administrative sides, link to several external sources (e.g., geocodes, UNLOCODES, time zones), and publish weekly updates. We will also answer your questions about national administrative and postal structures as we aggregated and curated all that data.
What are the extra 4 digits of my ZIP Code?
The extra four digits in a ZIP code are the ZIP+4 code. These additional digits provide a more precise location within a standard five-digit ZIP code area. They can help improve mail delivery accuracy, especially for large organizations or specific addresses, by narrowing down the delivery destination to a more specific location, such as a building or apartment within a complex.
What is the standard format for ZIP Code?
The standard format for a ZIP code in the United States is a five-digit number, such as “12345.” This basic code is used to identify a general geographic area. However, an extended ZIP+4 code, which includes an additional four digits, like “12345-6789,” can provide even more precise location information, helping to pinpoint specific addresses or buildings within that general area for more accurate mail delivery.
What are the four types of ZIP Codes?
The four types of ZIP codes in the United States are:
- Unique ZIP Codes: Assigned to individual organizations, government agencies, or large businesses.
- P.O. Box ZIP Codes: Specific codes designated for U.S. Postal Service P.O. Boxes.
- Standard ZIP Codes: Used for residential and commercial areas.
- Military ZIP Codes: Assigned to military facilities, with unique codes for domestic and overseas locations.
These categories help categorize and streamline mail delivery within the postal system.



